OS-research-lab
Spinlock Performance: Normal vs. Predictive AI
This simulation compares the performance of a Normal Spinlock against two “AI” (adaptive/predictive) spinlock strategies. The goal is to determine if an adaptive approach, which tries to predict lock hold times, can offer lower average wait costs compared to a simple spinlock that always spins.
Simulation Overview
The simulation evaluates three types of spinlocks:
- Normal Spinlock: Always spins (busy-waits) until the lock is acquired. The cost is the actual lock hold time.
- Heuristic AI Spinlock: An adaptive spinlock that uses an Exponential Moving Average (EMA) to predict lock hold times. It decides whether to spin or yield based on a threshold
T.Tis determined by a heuristic: the 90th percentile of the observed hold times in the test set.- If it yields or spins past
Tunsuccessfully, a static penaltyPis incurred.
- Tuned AI Spinlock: Similar to the Heuristic AI, but the threshold
Tis optimized via a grid search to find the value that minimizes the average wait cost for a fixed penaltyP.
Method & Equations
1. Data Generation
- Training Data (
N_trainsamples): Used to warm up the EMA predictor. Hold times are drawn from an exponential distribution (e.g.,scale=1.0) to simulate typically short, frequent operations. $h_{train} \sim \text{Exponential}(\lambda_{train})$ - Test Data (
N_testsamples): A mixture of short (e.g., 80%,scale=1.0) and long (e.g., 20%,scale=5.0) hold times, drawn from exponential distributions and shuffled to create a realistic workload. $h_{short} \sim \text{Exponential}(\lambda_{short})$ $h_{long} \sim \text{Exponential}(\lambda_{long})$
2. Exponential Moving Average (EMA) Predictor
Both AI spinlocks use an EMA to predict the next lock hold time. The prediction (pred) is updated after each observed hold time (h):
pred_new = α · h + (1 - α) · pred_old
Where:
pred_oldis the previous prediction.his the actual hold time just observed.- $\alpha$ is the smoothing factor (e.g., 0.1).
An initial prediction (
pred_initial) is established by “warming up” the EMA on the training data.
3. Cost Calculation
-
Normal Spinlock: The cost is simply the actual hold time
h. ` Cost_Normal = h` -
AI Spinlocks (Heuristic and Tuned): Let
Tbe the current spin threshold andPbe the static penalty for yielding/misprediction.- If
pred <= T(AI predicts a short hold):- If actual hold
h <= T(lock acquired within threshold):Cost_AI = h - If actual hold
h > T(lock not acquired within threshold, AI gives up):Cost_AI = T + P
- If actual hold
- If
pred > T(AI predicts a long hold and decides to yield immediately):Cost_AI = P
- If
4. Parameter Configuration (Example from Simulation Run)
- Smoothing Factor $\alpha = 0.1$
- Static Penalty $P = 5.0$ (units of time)
- For Heuristic AI: $T_{heuristic}$ is the 90th percentile of test hold times.
- For Tuned AI: $T_{best}$ is found by searching $T \in [0.1, 10.0]$ (example range).
Simulation Results
The following chart shows the average wait cost for each strategy from the sample simulation run you provided (image path images/000AAAspinglock.png):
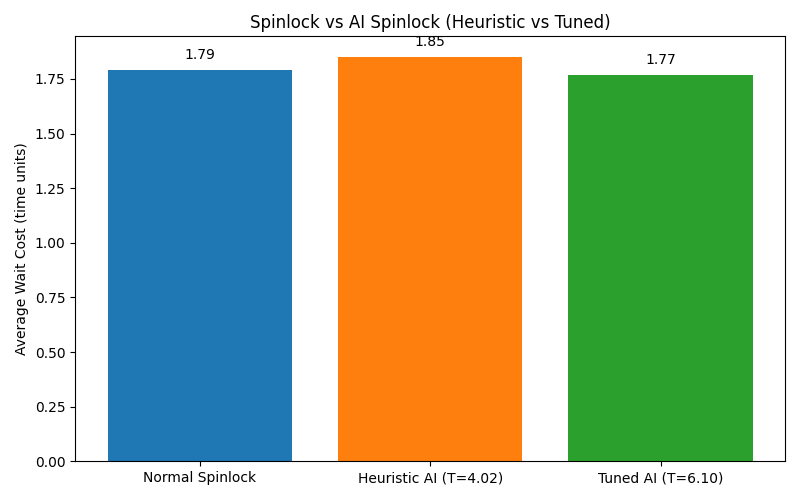
Results from the image:
- Normal Spinlock: Average Wait Cost = 1.79
- Heuristic AI (T=4.02): Average Wait Cost = 1.85
- Tuned AI (T=6.10): Average Wait Cost = 1.77
Analysis of Results (from the image)
In this particular simulation run:
- The Normal Spinlock provides a baseline average cost of 1.79 time units.
- The Heuristic AI Spinlock, with its threshold $T$ set to 4.02 (90th percentile of test hold times), performed slightly worse than the Normal Spinlock, with an average cost of 1.85. This suggests that this specific heuristic, while informed by the data, led to decisions (likely incurring $T+P$ penalties) that increased the average cost.
- The Tuned AI Spinlock found an optimal threshold $T_{best}$ of 6.10. It achieved an average cost of 1.77, which is marginally better than the Normal Spinlock. The high value of $T_{best}$ indicates that for the given penalty $P=5.0$, the optimal adaptive strategy was quite conservative, preferring to spin for a longer duration before considering yielding. This makes its behavior very similar to the Normal Spinlock, with a slight edge perhaps gained by correctly yielding (cost $P$) on some very long holds where $pred > T_{best}$.
Overall, these results highlight that while adaptive strategies can offer improvements, their effectiveness is highly dependent on the choice of parameters (T and P) and the accuracy of the predictor. In this instance, the Tuned AI showed a small benefit, while the specific Heuristic AI did not. The “Tuned AI” essentially learned that a very conservative spinning policy (high T) was optimal given the fixed penalty P.